On this page
Why You Can't Serve LLMs Like Regular Models (And How to Fix It)
Why I wrote this
Last year I went to the PyTorch Conference. Every other talk, every hallway conversation, every demo booth was about vLLM and SGLang. People were animated. People were arguing. I understood maybe one word in five.
My day job at the time was traditional data science — the kind where "inference" meant calling .predict() on a logistics ETA model that comfortably served ~2,000 requests per second on a single CPU pod. The infrastructure was someone else's problem because the infrastructure was not interesting: pickle, FastAPI, K8s, done.
Meanwhile two different worlds had been forming in parallel. One — the one I knew existed — was the world of "attention is all you need," scaling laws, fine-tuning, the model itself getting bigger and smarter. The other — the one I'd missed entirely — was the world of how on earth do you actually run these things once they're huge, autoregressive, and being consumed by humans typing impatiently into a chat box.
If you've ever watched Claude (or ChatGPT, or Gemini) stream a response into your browser one word at a time and wondered how a 70-billion-parameter monster sitting somewhere upstream can possibly keep up — that's the second world. And it turns out the answer is not boring infrastructure. It's twenty years of GPU programming, OS-level memory management, and clever scheduling tricks crammed into the last three years of papers, all happening at once.
Coming back from that conference I got obsessed with figuring out what vLLM even was. Which forced me to ask what inference even is, on a modern LLM. This essay is the long answer.
If you were to attend the 2026 PyTorch Conference — assuming you have a time machine — this is the piece that lets you sit through the vLLM keynote without feeling like you walked into a foreign-language film without subtitles. Or like you joined the third season of a show without watching the first two. Or like the person nodding politely in the back row of a graduate seminar at words they don't recognise. Pick your analogy. The goal is the same: to sit on the inside of the joke for once, instead of being the outsider in a room obsessed with something the rest of the internet hasn't quite heard of yet.
Let's start with what inference actually is.
What Is Inference?
If training an AI model is like sending a chef to culinary school for years, inference is putting that chef in a live Michelin-star kitchen on a Friday night at 8pm, taking real orders from paying customers who have expectations, dietary restrictions, and varying levels of patience — and delivering food that must feel magical every single time under extreme time pressure.
In the world of Generative AI, the single most important number is Tokens Per Second (TPS). A token is the atomic unit the model thinks in — roughly ¾ of a word on average in English. When you type a prompt and watch text appear, that streaming experience is the model emitting tokens one by one (or in small batches).
Good consumer experiences today sit in the 50–150 TPS range for small-to-medium models. High-end setups with heavy optimization can push 200–400+ TPS on dense models. Below ~30–40 TPS, the experience starts to feel sluggish. Below 15–20 TPS, users get frustrated and leave. Every extra token per second you can squeeze out of your GPUs is directly felt by every user.
images/llm-ar-loop.svg)Why LLM Inference Is Uniquely Difficult
Traditional machine learning inference (a ResNet classifying an image, a recommendation model scoring candidates) has very predictable characteristics:
- Fixed-size inputs (224×224 pixels, or a fixed feature vector)
- Fixed amount of computation per example
- Fixed-size outputs (a probability distribution over 1000 classes, or a single score)
Large Language Models break all three assumptions simultaneously:
- Variable-length inputs: A user can send 8 tokens or 128,000 tokens.
- Variable-length outputs: The model might stop after 12 tokens or keep going for 8,000.
- Autoregressive generation: Every new token depends on all previous tokens. You cannot parallelize the output the way you parallelize the input.
This combination creates five deep technical problems that simply do not exist in classical model serving. The rest of this essay exists to make you dangerous on all five.
Glossary — the words this essay uses
Skim this once, then come back when a term feels slippery. The whole essay assumes these.
TTFT — Time To First Token
Wall-clock time from "user pressed Enter" to "first token appears on screen." Dominated by prefill cost. For chat UX, below ~1 s feels instant, above ~3 s feels broken.
TPOT — Time Per Output Token (a.k.a. ITL, inter-token latency)
Average time between consecutive output tokens during decode. The reciprocal is the streaming TPS the user sees. 50–150 TPS feels good; below ~30 TPS feels sluggish.
Throughput vs Goodput
Throughput is total tokens/sec the cluster emits across all users. Goodput is throughput restricted to requests that met their latency SLO. A system can have great throughput and terrible goodput if it stuffs the batch so full that tails blow up.
p50 / p99 / p999 latency
Percentile latencies. p99 = "99 % of requests are faster than this." For LLM serving the tail (p99, p999) usually matters more than the median, because a single 8 s stall ruins the experience even if the average is fine.
Prefill vs Decode
Two phases of every LLM request. Prefill processes the whole prompt at once (compute-heavy). Decode generates one output token at a time (memory-bandwidth-heavy). Section 2 unpacks this.
KV cache
The Keys and Values that every attention layer computes for every prompt token. Caching them means decode only does work for the new token, not the whole history. Section 3 is entirely about managing it.
Batch vs Sequence
Batch = how many independent requests the GPU runs in one forward pass. Sequence length = how many tokens are in one request's prompt + generation so far. Continuous batching lets the batch composition change every iteration.
HBM, SRAM, FLOPs — the hardware words
HBM (High-Bandwidth Memory) is the GPU's main RAM — fast (~3 TB/s on H100) but small (~80 GB). SRAM is the on-chip scratchpad — tiny (~228 KB per SM) but ~10× faster. FLOPs = floating-point operations per second; an H100 does ~989 TFLOPs of dense FP16. The ratio FLOPs ÷ HBM-bandwidth is what makes a workload "memory-bound" or "compute-bound" — see the primer below.
Primer · The Roofline & the Memory Hierarchy
Before we get to the five differences, one mental model unlocks the rest of the essay: every operation a GPU runs is either compute-bound or memory-bound. Which one it is depends on a single ratio.
Arithmetic intensity, in one definition
Take any GPU kernel. Count the floating-point operations it performs. Count the bytes it reads from HBM. The ratio is arithmetic intensity — FLOPs per byte. That's the only number you need to predict whether the kernel will be limited by raw math or by data movement.
Every accelerator has its own ceiling. For an NVIDIA H100:
- Peak compute: ~989 TFLOPs FP16 / BF16 (dense), ~1.98 PFLOPs FP8
- HBM bandwidth: ~3.35 TB/s
- Crossover intensity: ~989 × 10¹² ÷ 3.35 × 10¹² ≈ 295 FLOPs/byte
Below ~295 FLOPs/byte on an H100, you are memory-bound — the GPU is faster than the data feeding it, so adding compute does nothing. Above it, you are compute-bound — adding bandwidth does nothing. The "roofline" plot draws both ceilings as two lines that form a roof; every kernel lives somewhere under the roof.
TFLOPs ▲
peak │ ━━━━━━━━━━━━━━ compute roof (~989 TF) ━━━
│ ╱ ◯ prefill (large batch)
│ ╱ ↑ compute-bound region
│ ╱
│ ╱ ◯ decode (batch ≈ 1)
│ ╱ ↑ memory-bound region
│ ╱ ← bandwidth roof (~3.35 TB/s slope)
└────────────────────────────────►
~10 ~295 arithmetic intensity (FLOPs/byte)
images/llm-roofline.svg)The memory hierarchy that drives the ratio
Memory bandwidth is not one number, it's a tower. From slowest-and-largest to fastest-and-tiniest on an H100:
┌────────────────────────┐ 80 GB · ~3.35 TB/s ← model weights, KV cache live here │ HBM3 │ ├────────────────────────┤ ~50 MB · ~5 TB/s ← shared cache, prefix re-use │ L2 cache │ ├────────────────────────┤ 228 KB/SM · ~20 TB/s ← Flash-Attention's playground │ SMEM (shared) │ ├────────────────────────┤ ~256 KB/SM · register · ~100+ TB/s effective │ Registers │ └────────────────────────┘
images/llm-memory-hierarchy.svg)Why this primer makes the rest of the essay click
Every section that follows is, in one sentence, an answer to "how do we move our kernels up the roofline?":
- Continuous batching raises arithmetic intensity by sharing the cost of loading weights across many concurrent requests.
- Prefill vs decode disaggregation sends compute-bound and memory-bound work to different hardware so neither starves the other.
- PagedAttention eliminates wasted HBM so you can afford a bigger batch — which raises intensity again.
- Quantization shrinks the bytes side of the ratio, directly moving every kernel rightward on the plot.
- Speculative decoding packs more useful work into each HBM read during decode.
Keep this picture in your head. The rest is mechanics.
1. Variable-Length Computation & Continuous Batching
The restaurant analogy: Traditional ML inference is a fast-food drive-thru. The menu is fixed, every car takes roughly the same amount of time, and the kitchen can plan perfectly. LLM inference is running the kitchen of a three-Michelin-star restaurant where one table orders a glass of water while the table next to them orders the full 18-course tasting menu with the wine pairing for every dish — and both tables expect their experience to feel equally special.
The Brutal Economics of Static Batching
In classical machine learning, the winning strategy for maximizing expensive GPU utilization is static batching: group several requests together and run them as one larger matrix multiplication. The fixed overhead of launching work on the GPU is amortized across many examples.
This strategy collapses with LLMs because of variable length computation.
Imagine you put four requests into a static batch:
- Request A: short prompt, generates 64 tokens
- Request B: medium prompt, generates 512 tokens
- Request C: long document, generates 2,048 tokens
- Request D: very long context, generates 8,192 tokens
Under static batching, the GPU finishes Request A after 64 steps but then sits mostly idle for the remaining ~8,000 steps while it waits for Request D. The three finished requests leave "holes" in the batch. Those holes represent extremely expensive silicon doing nothing.
At the scale of a real service (hundreds or thousands of requests per second), this waste compounds into millions of wasted GPU-seconds per day.
The Solution: Iteration-Level (Continuous) Batching
Modern LLM serving engines do something much more sophisticated.
They treat the batch as a fluid, living thing that is re-evaluated at every single decoding step.
The scheduler maintains a pool of active sequences. At each iteration it:
- Decides which sequences still need work
- Packs as many of them as will fit into the current batch (respecting memory and compute limits)
- Runs one forward pass
- Immediately evicts any sequences that just produced an end-of-sequence token
- Instantly admits new sequences from the waiting queue into the newly freed slots
This is only possible because of a beautiful property of transformer decoders: once you have computed the KV cache for the first n tokens of a sequence, computing token n+1 only requires the new token embedding plus the existing KV cache. The engine can pause a sequence, swap it out of the active batch, and resume it later with almost zero wasted work.
This technique is usually called continuous batching or iteration-level scheduling.
Why This Matters in Production
The Orca paper measured 2–7× higher throughput than FasterTransformer at matched latency. The vLLM SOSP'23 paper, building on iteration-level scheduling and adding PagedAttention, reported up to 24× higher throughput than HuggingFace TGI and 2–4× over the strongest prior systems. Teams moving from naive static batching to a modern engine routinely see the same range on their own workloads.
This is not a small optimization. This is the difference between needing 200 H100s and needing 60 H100s to serve the same traffic.
Continuous batching solves the problem of idle time. But packing the kitchen so tightly creates a new, more subtle bottleneck: the work of preparing the ingredients (processing the full prompt in the prefill stage) has radically different resource characteristics than the work of plating one element at a time (the decode stage). This brings us to the second fundamental difference — and one of the most important architectural decisions in modern LLM serving.
2. The Two Stages of Compute: Prefill vs Decode
The transition sentence from the previous section was deliberate. Once you embrace continuous batching, you quickly discover that not all work inside the batch is the same. Some work is extremely parallel and hungry for raw compute. Other work is painfully sequential and starved for memory bandwidth. Treating them identically is one of the most common (and expensive) mistakes in LLM serving.
The Kitchen Split: Prep Cooks vs Line Cooks
Continue the restaurant metaphor. In a real kitchen there are two very different kinds of work happening simultaneously:
- Prep work (mise en place): Reading the full order ticket, gathering and chopping ingredients, making stocks and sauces. This can be done in parallel by multiple people. Once the ingredients are ready, the actual cooking becomes much faster.
- Plating and finishing: The line cook actually cooking and assembling one dish at a time, plate by plate. This work is inherently sequential for a single order — you cannot plate the dessert before the main course is ready — and it is limited by how fast you can move things from the pass to the table.
LLM inference has an almost perfect analogue.
Prefill Stage: The Heavy Parallel Prep
When a request arrives, the model must first process the entire input prompt. This is called the prefill (or prompt processing) stage.
In the prefill stage the model runs a full forward pass over all input tokens at once. Every token's queries, keys and values are computed in parallel, and the prompt's GEMMs are large enough to push arithmetic intensity well past the H100 crossover at ~295 FLOPs/byte (see the roofline primer). At typical batch sizes this puts prefill firmly on the compute-bound side of the roof.
Self-attention is the part everyone fixates on. With the classical attention kernel, scores grow as O(n²) in both compute and memory — a 4 k prompt needs ~16× the attention work of a 1 k prompt. Flash Attention (Dao et al., v1 2022 → v3 2024 for Hopper) tiles the computation so the score matrix never materialises in HBM: memory becomes O(n), and wall-clock drops 2–4×. Every modern serving stack has it on by default; "attention is quadratic memory" is a 2021-era statement.
Decode Stage: One Token at a Time, Memory-Bound
Once the prefill is complete, the model switches to decode mode — generating output tokens one by one (or in small speculative bundles, see §6).
At each decode step the model only needs to compute attention for the single new token against all previous tokens (using the cached Keys and Values from earlier steps). The actual matrix multiplies for the new token are tiny — a few small GEMVs — compared with the cost of streaming the entire model weights and the growing KV cache out of HBM. Arithmetic intensity for single-stream decode lands in the single digits of FLOPs/byte, deep on the memory-bound side of the roof. Decode is therefore almost always memory-bandwidth-bound.
Why Mixing Prefill and Decode Destroys Predictability
When you run both phases on the same set of GPUs (the default in many early serving setups), they fight each other constantly.
A long prefill job (someone pasted a 20-page document) can occupy a large portion of the GPU's compute resources for hundreds of milliseconds. During that time, every decode step for other users slows down dramatically because the memory bandwidth and compute are being stolen. Users experience unpredictable "jitter" — sometimes responses stream smoothly, other times they stall for a second or two.
In latency-sensitive applications (chat, agents, copilots), this tail latency is often worse than the average latency. Users remember the bad experiences.
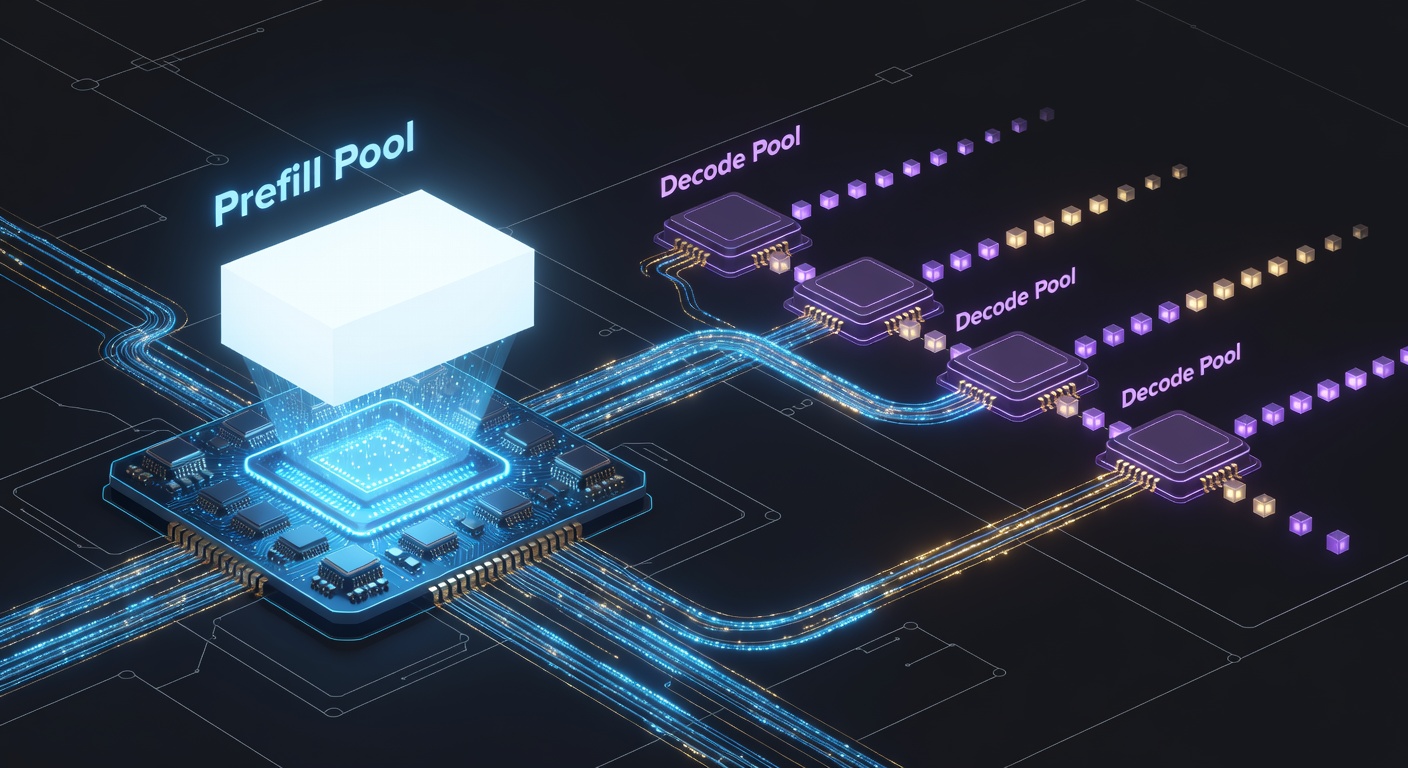
The Modern Solution: Prefill–Decode Disaggregation
The highest-performing large-scale systems now physically separate the two phases onto different pools of GPUs (or even different clusters).
Prefill pool: Optimized for high throughput and large batch sizes. These GPUs are usually packed with as much compute as possible (more SMs, higher clock speeds in some cases).
Decode pool: Optimized for low latency and memory bandwidth. These often use configurations that maximize HBM bandwidth per GPU and keep batch sizes smaller so each request gets predictable progress every few milliseconds.
When a prefill finishes, the KV cache for that request is transferred over NVLink (intra-node) or InfiniBand / RoCE (inter-node) to a decode GPU, and the request continues generating there. The transfer cost is real: for a 70 B-class model the KV cache can move at ~50–200 GB/s on modern interconnects, which dominates wall-clock for short prompts (<500 tokens) where the prefill itself was already cheap. DistServe (OSDI'24) and Microsoft's Splitwise (ISCA'24) measured this carefully and showed disaggregation paying off above roughly the 500–1 k-token prefill mark, with gains widening to 2–5× as prompts grow.
This pattern is now widely adopted. SGLang has native support for prefill–decode (PD) disaggregation; vLLM ships it from v0.6 onwards. Ray Serve + vLLM or TensorRT-LLM combinations are commonly used in production to orchestrate the handoff.
The Pragmatic Alternative: Chunked Prefill
Disaggregation is not the only way out. Chunked prefill — the headline idea of the SARATHI-Serve paper (Agrawal et al., 2024) — keeps prefill and decode on the same GPU but slices each long prefill into small chunks (e.g. 512 tokens) and interleaves them with ongoing decode iterations. Each step of the scheduler processes "a little prefill chunk + many decode tokens" together. Three properties fall out:
- The decode stream is never blocked for more than one chunk's worth of compute (~10–50 ms), so the tail-latency problem disappears.
- The mixed step has higher arithmetic intensity than pure decode, so per-step throughput goes up.
- There is no KV transfer because nothing moves between GPUs.
vLLM v1 and SGLang both default to chunked prefill out of the box. It's strictly simpler than disaggregation and captures most of the latency benefit; disaggregation still wins at very large scale, very long prompts, or when you want to tune prefill and decode hardware independently.
When to consider disaggregation vs chunked prefill: If you're running a single fleet on a single SKU, chunked prefill is the right default. Switch to disaggregation when prefill cost is dominating your spend (long-document RAG, code-base summarisation), when you want to mix H100s for prefill with B-series or cheaper hardware for decode, or when your prompts are large enough that the transfer is comfortably amortised.
Separating the two stages buys you much more predictable performance. But now every request that moves between pools carries with it a growing pile of state — the KV cache — that must be stored, managed, and eventually reclaimed. This state management problem is dramatically harder than anything classical model serving ever had to deal with. That brings us to the third (and arguably most important) difference.
3. GPU Memory Management & The KV Cache
Continuing the kitchen story: once continuous batching and disaggregation have made the line move efficiently, a new problem emerges. Customers are not ordering single dishes in isolation. They are having long, multi-course conversations with the kitchen.
Every time a regular customer returns and says "the usual, plus can I get the wine pairing this time?", the kitchen does not want to re-read the customer's entire previous order history from scratch just to remember what they liked last time. That history is extremely valuable state.
In LLMs, this state is the KV cache — and managing it efficiently is one of the hardest and most important problems in production serving.
What the KV Cache Actually Is
During the forward pass, the model computes Key and Value projections for every token at every layer (and every attention head). In the decode phase, instead of recomputing attention over the entire history from scratch for every new token, the model reuses these previously computed K and V vectors.
The size of this cache is linear in context length and given exactly by:
KV bytes = 2 × L × Hkv × dhead × seq_len × bytes/value
The leading 2 is "one tensor for K, one for V." L = number of layers, Hkv = number of KV heads (not query heads), dhead = per-head dimension, bytes/value = 2 for FP16 / BF16, 1 for FP8 / INT8.
Worked example. For a Llama-3 70 B-class model (L = 80, Hkv = 8, dhead = 128, FP16 = 2 bytes), one 8 192-token request:
2 × 80 × 8 × 128 × 8 192 × 2 ≈ 2.68 GB
- One 8 k-context request: ≈ 2.7 GB just for KV.
- 64 concurrent 8 k requests: ≈ 170 GB — more than two H100s' worth of HBM, before model weights.
- One 128 k-context request: ≈ 42 GB. The model weights (~140 GB in FP16) are no longer the dominant memory consumer.
This is frequently the largest memory consumer in high-concurrency serving, far larger than the model weights themselves for long-context workloads. Modern stacks therefore also quantize the KV cache (FP8 or INT8) and use sliding-window or attention-sink tricks for very long sequences — see §3.5.
The Fragmentation Crisis
Early serving systems allocated the KV cache for each sequence as one giant contiguous block in GPU memory. This worked fine for short, uniform requests.
In the real world it collapses. Requests arrive and depart at different times with wildly different lengths. A conversation that started at 2k tokens might grow to 32k over 20 turns. Other requests finish and free their memory. You quickly end up with classic external fragmentation: plenty of free memory in aggregate, but no single contiguous slab large enough for a new long request.
This is the GPU equivalent of trying to seat a party of 12 when you only have scattered tables of 2 and 4 left.

The Breakthrough: PagedAttention (vLLM, 2023)
The vLLM team at UC Berkeley solved this by importing one of the most successful ideas in computer science: virtual memory and paging, invented in the 1960s for operating systems.
Instead of allocating one massive contiguous region per sequence, PagedAttention divides the KV cache into small, fixed-size blocks (typically 16 or 32 tokens worth of K/V vectors). These blocks can live anywhere in GPU memory. A lightweight block table (exactly analogous to a page table in an OS) keeps track of which logical blocks map to which physical memory locations.
Benefits, as measured in Kwon et al. (SOSP'23):
- Elimination of external fragmentation — any free block can be used by any sequence.
- Efficient sharing of prefix blocks across multiple requests (the foundation for later prefix caching, beam search and parallel sampling).
- Memory waste drops from 60–80 % in naïve allocators (FasterTransformer, early TGI) to under 4 % with paging — almost all reserved-but-unused fragmentation is eliminated.
That headroom is what lets the engine push the batch size up. End-to-end, vLLM reported up to 24× higher throughput than HuggingFace TGI and 2–4× over FasterTransformer at matched latency. PagedAttention became the foundation for virtually every serious open-source and commercial LLM inference engine that followed.
Beyond Paging: Real-World KV Cache Management
Paging solved fragmentation, but production systems still face hard questions:
- Prefix caching: When two requests share a long prefix (same system prompt + same uploaded document), can we share the KV blocks instead of recomputing them?
- Eviction policies: When memory is full, which sequences' caches should be discarded or swapped to CPU?
- Recompute vs cache trade-offs: For very long contexts in RAG, sometimes it is cheaper to drop old blocks and recompute them later than to keep everything resident.
Modern engines (SGLang's radix tree, vLLM's advanced prefix caching, TensorRT-LLM's features) combine paging with sophisticated prefix matching and eviction logic. This is no longer a simple cache — it is a full distributed memory management system for attention state.
Efficiently managing the KV cache is table stakes. But the cache is only valuable if you route new requests to the specific GPUs that already hold the relevant prefixes. Naively load-balancing without looking at what is cached destroys all the efficiency you just built. Before we get there, though, there's a single lever that shrinks every number in this section by a factor of two or four. It deserves its own short section.
3.5 Quantization · The Single Biggest Cost Lever
Every byte the GPU reads from HBM is a byte that contributes to the memory-bound side of the roofline. The simplest way to read fewer bytes is to use fewer bits per number. That is what quantization does — and on memory-bound workloads (decode, KV-cache reads, long-context attention) the speed-up is close to the raw byte ratio, often essentially free.
The number-format ladder
Modern serving stacks use a spectrum of precisions, often different ones for different tensors in the same model:
bits bytes decode× accuracy hit notes FP32 32 4 0.5× none training only BF16 16 2 1.0× none modern training default FP16 16 2 1.0× none old serving default FP8 8 1 ~2.0× <0.5 pt MMLU H100+ native; Llama-3 FP8 ≈ FP16 INT8 8 1 ~2.0× <1 pt SmoothQuant; pre-Hopper standard INT4 4 0.5 ~3–4× 1–3 pt AWQ / GPTQ; the workhorse for 70 B+
images/llm-quant-spectrum.svg)Three things you can quantize, three different stories
- Weights. The frozen model parameters. Easiest target. AWQ (Lin et al., 2023) and GPTQ (Frantar et al., 2022) are the dominant weight-only methods at 4-bit; both run calibration over a small dataset and round most weights aggressively while protecting a few "salient" channels.
- Activations. The intermediate tensors flowing through the network at inference time. Harder, because activations have long-tailed distributions (a few outliers ruin naive rounding). SmoothQuant (Xiao et al., 2022) is the classic fix — rescale the outliers into the weights so activations become well-behaved. Hopper-class GPUs have native FP8 tensor cores, which makes FP8 activations the practical default for new deployments.
- The KV cache. Often the largest tensor at long context. Quantizing it from FP16 to FP8 halves KV memory, which roughly doubles the batch size you can afford, which more or less doubles throughput. FP8 KV cache is "ship it" advice; INT4 KV is research-grade today but improving fast.
Why this is the highest-ROI lever in the essay
Continuous batching and PagedAttention each give 2–4× over a 2022 baseline. Quantizing a 70 B model from FP16 to INT4-weights + FP8-activations + FP8-KV typically gives another 2–3× throughput on top, for < 1 point of MMLU. It's the single biggest lever a team can pull in a week, and it composes with everything else in this essay.
If you take one operational suggestion away from this essay: before reaching for a bigger GPU, try FP8 KV cache and a properly calibrated AWQ-int4 build of your current model. The cost curve falls off a cliff.
With memory shrunk and the KV cache under control, we can return to the question we left open: even an efficient cache is useless if the router doesn't know which GPU holds it. That's the fourth fundamental difference.
4. Prefix-Aware Routing
By this point in the kitchen story, the implications should be clear. The most valuable thing in the restaurant is not the stoves or the plates — it is the institutional memory. The head waiter who knows that Table 7 always wants the sommelier's recommendation, that the couple at Table 12 had the 2018 Bordeaux last time and loved it, and that the solo diner at Table 3 is deathly allergic to pine nuts.
When a regular customer returns, you do not seat them with a random waiter who has never met them before. That would be terrible service and a massive waste of the head waiter's knowledge.
In LLM serving, the equivalent of that institutional memory is the KV cache. And most traditional load balancers are the equivalent of seating every returning customer with a random waiter.
The Expensive Mistake
Consider a typical RAG application:
- User uploads a 40-page legal contract or research paper (≈ 8,000–12,000 tokens).
- The system runs prefill, computes the KV cache for that document (this might take 2–8 seconds on a good GPU, depending on model size).
- The user then asks 15–20 follow-up questions over the next hour ("What does Clause 7.3 say about liability?", "Summarize the indemnity section", etc.).
Each of those follow-ups shares almost the entire prefix with the original document. If the load balancer sends the second question to a different replica than the first, that replica has to re-run the entire prefill from scratch. You just paid the full quadratic attention cost again for no reason.
In practice, this is one of the most common reasons "our RAG system is slow and expensive" — the system is recomputing the same expensive prefixes over and over because the router is prefix-blind.
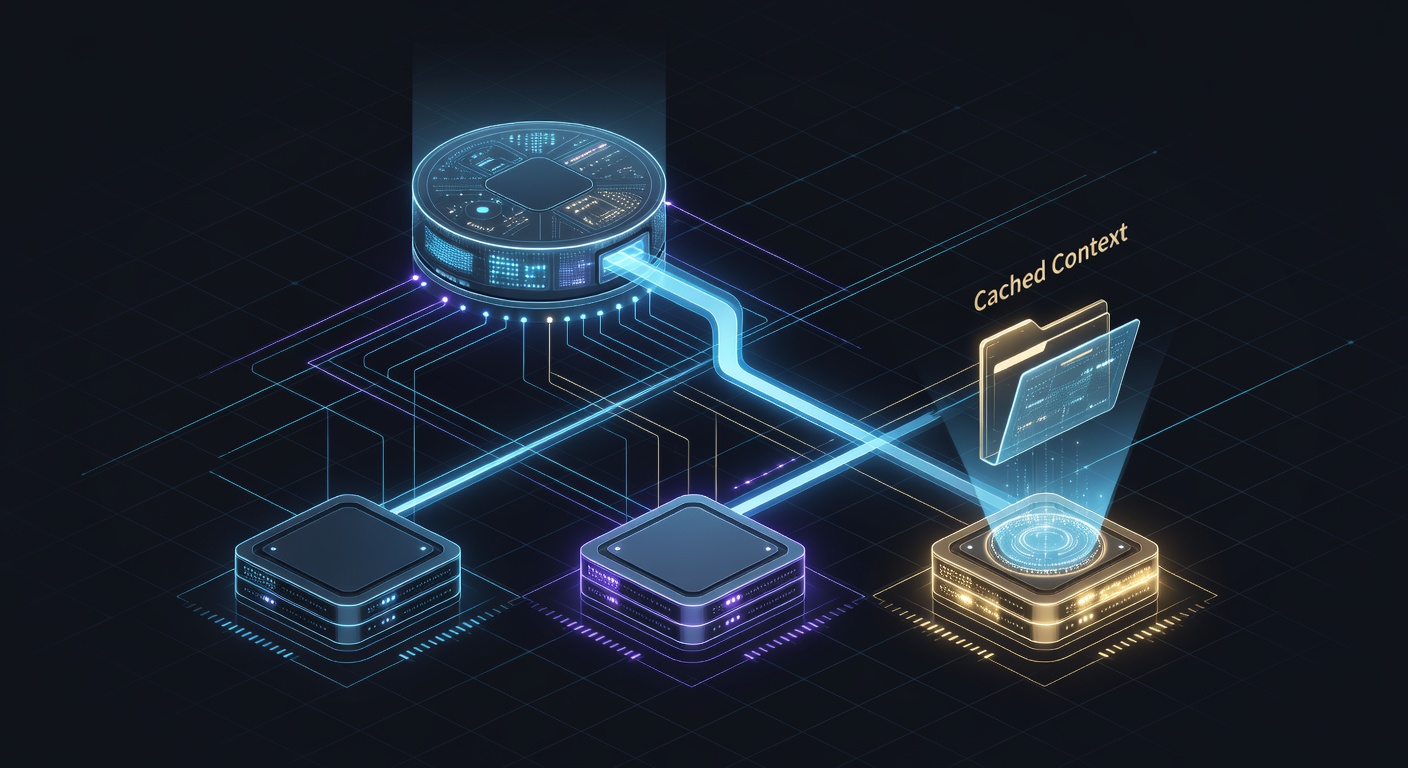
How Prefix-Aware Routing Actually Works
A prefix-aware router does not treat every incoming request as an independent unit. Instead, before deciding where to schedule a request, it inspects the prompt (or a compact representation of it) and asks: "Have we already computed the KV cache for any prefix of this prompt? If so, where is that cache currently resident?"
There are several levels of sophistication:
- Simple hash-based: Hash the first N tokens (or the system prompt + document ID) and route to any replica that has previously seen that hash.
- Radix tree / Trie-based (used in SGLang): Maintain a tree of all active prefixes across the cluster. This allows extremely fast longest-prefix matching and also enables efficient sharing of common prefixes between different users (e.g., the same system prompt used by thousands of users).
- Distributed prefix cache: The router (or a dedicated prefix cache service) keeps metadata about which nodes hold which prefix blocks. It can then either route the request to one of those nodes or, in advanced setups, migrate the relevant KV blocks to a less-loaded node.
The key insight is that the routing decision must happen *before* the request is assigned to a GPU. Once the request is already running on the wrong node, it is usually too late to fix without wasting the work that was just done.
Why This Is Harder Than It Sounds
Implementing good prefix-aware routing at scale introduces real engineering challenges:
- Prefixes are not always exact matches (a user might paste almost the same document with tiny formatting differences).
- The prefix cache itself consumes memory and needs its own eviction policy.
- In a distributed system, the router needs a consistent, low-latency view of where every active prefix block lives.
- There is a tension between maximizing cache hits (route to wherever the prefix lives) and load balancing (don't overload the one node that happens to have a popular prefix).
This is why you see specialized systems (SGLang's radix tree, custom routers in Ray Serve, various internal systems at large labs) rather than "just use Nginx or a generic load balancer."
Production Impact
In workloads with high prefix overlap (most real RAG applications, multi-turn agents, coding copilots with repository context, etc.), good prefix-aware routing can easily deliver 3–10× better effective throughput and dramatically lower latency for follow-up turns. It is one of the highest-leverage optimizations once you are past the basics of continuous batching and PagedAttention.
We now have efficient ways to keep the kitchen moving (continuous batching), separate the heavy prep from the delicate plating (disaggregation), and remember everything the customer has ever said without wasting memory (PagedAttention + prefix caching). But what happens when the recipe book itself is so large and specialized that no single chef can possibly know the whole thing? This is the world of Mixture-of-Experts models — and it forces us into the fifth and final fundamental difference.
5. Model Sharding & Mixture of Experts
We have now reached the final and most structurally different challenge.
Imagine a Michelin-star kitchen where the recipe book has grown so large and specialized that no single chef — no matter how talented — can possibly master every technique at the level required. The solution the restaurant adopts is to hire a team of world-class specialists: a dedicated pastry chef, a grill master, a saucier, a sushi specialist, a fermentation expert, and so on. For any given dish, only two or three of these specialists actually touch the plate. The head chef (the "gating network") decides, based on the order coming in, which experts are needed for each component.
This is exactly the architecture behind modern Mixture-of-Experts (MoE) models — and it completely changes how you must think about model parallelism and serving infrastructure.
The Efficiency Promise of MoE
In a traditional dense model, every parameter is used for every token. In an MoE model, the total number of parameters can be enormous (hundreds of billions or even trillions), but only a small subset are activated for any given token.
Classic examples:
- Mixtral 8x7B: ~47B total parameters, but only ~12–13B active per token (2 experts out of 8).
- Grok-1 (314B): 8 experts, 2 active.
- DeepSeek-V2 / V3 and many frontier models: even more aggressive sparsity.
The result during training is dramatically better performance per FLOP. You get the capacity of a much larger model while only paying the compute cost of a smaller one. This is why so many of the strongest open-weight models in 2024–2025 are MoE architectures.

The Inference Reality: Token-Level Dynamic Routing
What makes MoE models beautiful for training makes them painful for inference if your infrastructure isn't designed for them.
In a dense model, the computation graph is static. Every token goes through exactly the same layers on the same GPUs.
In an MoE model:
- The attention layers are usually dense and replicated across all GPUs (everyone needs them).
- The feed-forward layers are replaced by many expert feed-forward networks.
- A small gating/router network looks at each token and decides which 1–2 (or top-k) experts should process it.
- Those tokens are then dispatched to the specific GPUs that hold the chosen experts.
- After the expert computation, the results are combined and sent back.
This dispatch-and-combine step happens at the granularity of individual tokens, inside the forward pass. It creates highly dynamic, data-dependent all-to-all communication patterns between GPUs that change on every single forward pass depending on the content of the prompt.
How Teams Actually Shard These Models
Production MoE serving is almost never one form of parallelism — it's a stack of four, each cutting a different dimension of the problem:
- EP (Expert Parallelism) — different experts live on different GPUs. Activated tokens fly to the GPU that owns their expert via an all-to-all collective, then results fly back.
- TP (Tensor Parallelism) — within a single layer, weight matrices are split across GPUs (Megatron-LM style). Used for attention and for the dense parts of the expert MLPs.
- DP (Data Parallelism) — entire replicas of the model running in parallel on independent batches. The outer dimension.
- PP (Pipeline Parallelism) — different layers on different GPUs. Less common at inference but reappears for very large models.
A typical DeepSeek-V3 or Mixtral 8×22B serving topology looks like EP × TP × DP simultaneously — e.g. 8-way EP across the experts of one layer, 2-way TP inside each expert's weight matrices, and 4-way DP on top for throughput. There is no single right answer; tuning the (EP, TP, DP, PP) tuple for a given model, GPU count and SLO is a real chunk of MoE-serving engineering.
On top of that, you have to manage MoE-specific knobs:
- Top-k routing. Each token picks k experts (usually 2). Bigger k means more quality but proportionally more compute and communication.
- Expert capacity / token dropping. Because routing is content-dependent, some experts get more tokens than others on any given batch. To make the all-to-all a fixed-size collective, each expert has a capacity (max tokens it will accept this step); any overflow is dropped (sent through a residual path) or rerouted. Setting capacity too low hurts quality; too high wastes bandwidth.
- Load balancing. Auxiliary losses during training keep the long-run expert distribution roughly uniform, but at inference the router still benefits from runtime tricks — expert replication for the "hot" experts, smart token-to-GPU assignment, or even microbatch-level rebalancing.
The communication volume is significantly higher than in dense models. A naive implementation will spend more time moving tokens between GPUs than actually computing on them, which is why overlapping the all-to-all with the local expert compute is itself a research area.
Why Generic Infrastructure Fails Here
Most traditional model servers assume a static computation graph. They have no concept of "this token needs to go to GPU 7 right now because that's where Expert 3 lives, while the next token from the same sequence needs to go to GPU 2."
This is why serving large MoE models on generic infrastructure is usually a painful, low-utilization experience. You need deep integration between the model architecture and the serving engine.
Today, the best support exists in:
- TensorRT-LLM (very strong MoE support from NVIDIA)
- vLLM and SGLang (rapidly improving, with good expert parallelism and dynamic routing)
- Custom internal stacks at the largest labs
Production Implications
If you are planning to serve (or fine-tune and then serve) one of the new generation of large open MoE models, you should assume from day one that you will need one of the specialized engines above. Trying to force it into a generic vLLM or Hugging Face Text Generation Inference setup without MoE-aware scheduling will leave large amounts of performance on the table and create operational headaches around load imbalance and communication overhead.
This is the final reason why "just use the same serving stack we used for our 7B model" almost never works at the frontier.
We have now walked through the five fundamental architectural differences. There's one more technique that deserves its own short section — not because it's structurally different from dense serving, but because it's the single most clever idea anyone has had about decode in the last three years.
6. Speculative Decoding · Free Tokens From Cheap Guesses
Decode is memory-bound. Each step reads the entire ~140 GB of a 70 B model's weights out of HBM just to produce one token. The compute units sit ~95 % idle waiting for bytes. The obvious question: since the GPU has so much compute to spare on every decode step, can we make it produce more than one token per HBM read?
Speculative decoding (Leviathan et al., 2022; Chen et al., 2023) says yes. The trick:
- Run a tiny, fast draft model (e.g. a 1 B model alongside a 70 B target) to guess the next k tokens autoregressively. This is cheap — the draft model is small.
- Run a single parallel forward pass of the big target model over all k draft tokens at once. This is one HBM read of the big weights, but produces k logits in parallel.
- For each position, accept the draft token if its probability under the target model matches a rejection-sampling criterion; reject and resample from the target's distribution at the first mismatch.
Crucially, the procedure is mathematically equivalent to vanilla sampling from the target model — no quality loss, no behavioural drift. You're just amortising the big model's HBM read across multiple tokens.
draft model (1B): ●→●→●→●→● k=5 cheap autoregressive steps
↓ ↓ ↓ ↓ ↓
target model (70B): ──────█────── one parallel forward pass
✓ ✓ ✓ ✗ ·
verified output: "the cat sat" (3 accepted, 1 rejected & resampled)
net result: 4 tokens emitted for the cost of 1 big read
images/llm-spec-decode.svg)The families of speculation
- Vanilla draft-model. A small separate model (e.g. Llama-3 1 B drafting for Llama-3 70 B). Acceptance rate ~60–80 % for typical English text, 2–3× decode wall-clock speed-up.
- Self-speculative / Medusa (Cai et al., 2024). The target model itself grows a handful of extra "Medusa heads" that predict the next k tokens directly. No separate draft model to host, but you need to fine-tune the heads.
- EAGLE / EAGLE-2 (Li et al., 2024). The draft is a small autoregressive head sitting on top of the target's last hidden layer, conditioning on the target's own features. Currently the strongest reported acceptance rates (3–4× speed-ups on chat workloads).
- Lookahead decoding (Fu et al., 2024). No draft model at all — generates and verifies n-grams directly from the target. Wins when you can't host a second model.
When speculation pays, when it doesn't
The math is unforgiving:
- It helps when you're memory-bound — single-stream decode, low batch sizes, latency-sensitive workloads. This is where the spare compute lives.
- It hurts when you're already compute-bound — large batches doing decode (the weight read is already amortised) or any prefill workload. The extra work of running the draft and verifying rejected tokens is pure overhead.
- Acceptance rate is the whole game. Drafts that match the target ~80 % of the time yield real speed-ups; ~40 % is break-even; below that you've made things slower.
vLLM, TensorRT-LLM and SGLang all support speculative decoding behind a flag. For latency-critical single-user-per-GPU products (coding copilots, voice agents, on-device chat), it's often the difference between "good" and "magical."
Six techniques, one mental model. Let's pull the thread.
Conclusion · One Ratio, Seven Angles
If the kitchen metaphor did its job, you no longer see "LLM serving" as a grab-bag of buzzwords. You see a single, ugly, beautiful ratio — FLOPs per byte — being attacked from seven different angles, each of which moves your kernels up or right on the roofline plot from §0.5.
Continuous batching shares one HBM read of the weights across many users. Prefill–decode disaggregation (and its quieter cousin, chunked prefill) refuses to let compute-bound and memory-bound work fight over the same GPU. PagedAttention reclaims the wasted HBM so you can afford a bigger batch — which raises arithmetic intensity again. Prefix-aware routing makes the most expensive thing the system ever computes — the KV cache — a first-class scheduling input. MoE sharding lets you scale capacity faster than activations. Quantization shrinks the bytes side of the ratio directly. Speculative decoding packs more useful tokens into every big-model HBM read.
They are not seven tricks. They are one ratio, attacked seven ways.
The teams that internalize this stop chasing optimizations as a checklist and start asking the only question that matters: where on the roofline does this kernel live, and what's the cheapest move that puts it somewhere better? The answer is usually one of the seven above, sometimes a combination, occasionally something nobody has written up yet.
If you want the abstract knowledge to become operator instinct: open the Appendix, follow the three steps tonight, and stare at the p99 numbers until they tell you which lever to pull next. That's the whole job.
The mental model is the gift. The benchmark output is where it pays rent.
Video Companion
This written piece expands significantly on a conversation I had while riding bikes (yes, really). The video version covers the high-level intuition. The post you're reading goes much deeper into mechanisms, numbers, and production implications.
YouTube embed will be inserted here once the video is uploaded.
Check back soon or follow me on X/Twitter for the announcement.
Appendix · Your First Inference Stack
If you've never deployed an LLM yourself, the smallest possible useful stack fits on one GPU and one screen. Here's the path that turns this essay's concepts into something you can poke at tonight.
Step 1 · Run a real engine, not model.generate()
Both vLLM and SGLang ship with a one-liner that already includes continuous batching, PagedAttention, prefix caching and (in recent versions) chunked prefill:
# vLLM — drop-in OpenAI-compatible server
pip install vllm
# Llama-3 8B Instruct, FP16, on one H100/A100
vllm serve meta-llama/Meta-Llama-3-8B-Instruct \
--max-model-len 8192 \
--gpu-memory-utilization 0.90
# Or the SDK form, equivalent under the hood:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Meta-Llama-3-8B-Instruct",
max_model_len=8192)
out = llm.generate(["Why is the sky blue?"],
SamplingParams(temperature=0.7, max_tokens=256))
print(out[0].outputs[0].text)You now have continuous batching, paged KV, and an OpenAI-shape /v1/chat/completions endpoint at localhost:8000.
Step 2 · Benchmark it like you mean it
Don't trust your eyes — measure TTFT, TPOT and throughput under realistic concurrency:
# vLLM ships a serving benchmark — runs N concurrent clients,
# measures p50 / p99 TTFT and inter-token latency:
python -m vllm.entrypoints.benchmark_serving \
--backend openai \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--dataset-name sharegpt --num-prompts 1000 \
--request-rate 8Stare at the p99 TTFT and TPOT numbers. Then double the concurrency and stare again. This is how you build operator intuition.
Step 3 · Push every lever in this essay
- Turn on chunked prefill (
--enable-chunked-prefillin vLLM) and re-run the benchmark. - Quantize: pull an AWQ-int4 build of the same model (
TheBloke/Meta-Llama-3-8B-Instruct-AWQor similar) and compare throughput at matched p99 latency. - Enable FP8 KV cache (
--kv-cache-dtype fp8on H100+). - Pass two replicas behind a router that hashes on the system prompt — that's your prefix-aware routing baseline.
- Try speculative decoding with a 1 B draft model (
--speculative-model).
By the end of the weekend you will have lived every section of this essay in numbers on your own hardware. That's the difference between knowing about LLM serving and being dangerous at it.
Further Reading & Primary Sources
Foundational papers
- Kwon et al., "Efficient Memory Management for Large Language Model Serving with PagedAttention" (vLLM) — SOSP 2023
- Yu et al., "Orca: A Distributed Serving System for Transformer-Based Generative Models" — OSDI 2022
- Dao et al., "FlashAttention" (v1 2022) / "FlashAttention-2" (2023) / "FlashAttention-3" (2024, Hopper)
- Ainslie et al., "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" — 2023
Disaggregation & scheduling
- Zhong et al., "DistServe: Disaggregating Prefill and Decoding for Goodput-Optimized LLM Serving" — OSDI 2024
- Patel et al., "Splitwise: Efficient Generative LLM Inference Using Phase Splitting" (Microsoft) — ISCA 2024
- Agrawal et al., "SARATHI-Serve: Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve" — 2024 (chunked prefill)
- Qin et al., "Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving" (Moonshot AI) — 2024
Quantization & speculative decoding
- Lin et al., "AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration" — 2023
- Frantar et al., "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers" — 2022
- Xiao et al., "SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models" — 2022
- Leviathan et al., "Fast Inference from Transformers via Speculative Decoding" — 2022
- Cai et al., "Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads" — 2024
- Li et al., "EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees" — 2024
Frameworks & docs
- vLLM documentation — continuous batching, PagedAttention, chunked prefill, PD disaggregation
- SGLang documentation — RadixAttention, prefix-aware routing, structured generation
- TensorRT-LLM documentation — strong MoE and Hopper FP8 support
- Ray Serve + LLM — orchestration across vLLM / TensorRT-LLM workers